Proste wyjaśnienie
Wyobraź sobie, że masz ogromną bibliotekę wypełnioną milionami książek na wszystkie możliwe tematy. Teraz wyobraź sobie superinteligentnego bibliotekarza, który przeczytał wszystkie te książki i potrafi szybko znaleźć potrzebne Ci informacje lub stworzyć nowe, unikalne historie na podstawie tego, co przeczytał.
Duży model językowy, taki jak GPT-4o (który jest tylko jednym z wielu typów), działa w podobny sposób. Oto proste zestawienie:
- Uczenie się z tekstów: Najpierw GPT-4o został wytrenowany na ogromnej ilości tekstów z książek, artykułów, stron internetowych i wielu innych źródeł. Podczas tego procesu uczy się wzorców, gramatyki, faktów, a nawet pewnych umiejętności rozumowania. To tak, jakby uczyć superinteligentnego bibliotekarza, pozwalając mu przeczytać miliony książek.
- Rozumienie kontekstu: Kiedy zadajesz GPT-4o pytanie lub podajesz mu polecenie (prompt), model nie analizuje słów pojedynczo. Zamiast tego rozumie kontekst, co oznacza, że przygląda się całemu zdaniu, akapitowi, a nawet całej rozmowie, aby sformułować najlepszą odpowiedź. To tak, jakby poprosić naszego bibliotekarza, aby zrozumiał nie tylko jedno słowo, ale całą historię, która go otacza.
- Generowanie odpowiedzi: Po zrozumieniu kontekstu GPT-4o generuje odpowiedź. Nie powtarza on po prostu tego, co przeczytał; łączy fragmenty informacji w nowy sposób, aby stworzyć sensowną odpowiedź. Wyobraź sobie, że nasz bibliotekarz nie cytuje po prostu książki, lecz tworzy nowe streszczenie lub opowieść na podstawie wszystkiego, czego się nauczył.
- Doskonalenie odpowiedzi: Model jest zaprojektowany tak, aby udzielać dokładniejszych i bardziej trafnych odpowiedzi. Robi to poprzez przewidywanie kolejnego słowa w zdaniu na podstawie słów poprzednich, dopracowując odpowiedź tak długo, aż stanie się ona zrozumiała. Nasz bibliotekarz robi to samo, uważnie zastanawiając się nad każdym wybranym słowem, aby upewnić się, że wyjaśnienie jest jasne.
Podsumowując, GPT-4o jest jak superinteligentny bibliotekarz, który przeczytał i przyswoił treści z ogromnej biblioteki tekstów. Rozumie Twoje pytania, analizując cały kontekst, a następnie generuje nowe, sensowne odpowiedzi na podstawie zdobytej wiedzy. Dzięki temu może pomagać w szerokim zakresie zadań — od odpowiadania na pytania, po pisanie esejów czy opowiadań.
Bardziej szczegółowe wyjaśnienie
Zrozumienie dokładnie jak działają LLM-y (Large Language Models) jest niezwykle złożone i wymaga głębokiej wiedzy z zakresu matematyki i informatyki. Dlatego znacznie ważniejsze jest, abyś wiedział, co one robią. Proces ten składa się z sekwencji skomplikowanych działań, począwszy od tokenizacji danych treningowych, aż po generowanie odpowiedzi. Oto wyjaśnienie krok po kroku:
-
Tokenizacja:
Tokenizacja to pierwszy krok w przygotowaniu danych dla LLM-ów. Proces ten polega na rozbijaniu surowego tekstu na mniejsze, łatwiejsze do zarządzania jednostki zwane tokenami. Tokenami mogą być całe słowa, części słów (podsłowa), a nawet pojedyncze znaki, w zależności od poziomu szczegółowości wymaganego dla zadań modelu. Tokenizacja pomaga w obsłudze różnorodności języka poprzez standaryzację danych wejściowych i sprawienie, że będą one obliczalne dla sieci neuronowych.
OpenAI posiada bardzo przejrzysty interfejs, który pozwala zobaczyć, jak działa ich tokenizator! Jeśli pobawisz się nim przez kilka minut, ta koncepcja stanie się znacznie jaśniejsza.
-
Kodowanie informacji pozycyjnych:
Gdy dane tekstowe zostaną ztokenizowane, kolejnym krokiem jest embedding (tworzenie zanurzeń), gdzie każdy token jest konwertowany na wektor numeryczny, który model może przetworzyć. Embeddingi reprezentują tokeny w sposób, który zachowuje znaczenie semantyczne, co pozwala słowom lub tokenom o podobnym znaczeniu mieć zbliżoną reprezentację w przestrzeni wektorowej (matematycznym modelu wielowymiarowej przestrzeni).
Embeddingi mogą być tworzone za pomocą różnych technik. Jednak bardziej zaawansowane LLM-y często wykorzystują metody oparte na sieciach neuronowych, aby uczyć się tych zanurzeń bezpośrednio z danych. Obejmuje to metody takie jak Word2Vec i ELMo, w których embeddingi są trenowane w celu przewidywania kontekstów językowych słów, co skutecznie oddaje głębsze znaczenia semantyczne i syntaktyczne języka.
W uproszczeniu możesz wyobrazić sobie embeddingi jako znaczące punkty w bardzo wysokowymiarowej przestrzeni, do której dostęp ma tylko komputer, ponieważ ludzki mózg potrafi realnie myśleć jedynie w trzech wymiarach.
-
Mechanizm uwagi (Attention Mechanism):
Sercem modelu typu Transformer, na którym opiera się większość LLM-ów, jest mechanizm uwagi. Pozwala on modelowi skupić się na różnych częściach sekwencji wejściowej w zależności od potrzeb. Mechanizm uwagi oblicza wagi, które określają, jak dużą uwagę należy zwrócić na inne części danych wejściowych dla każdego tokena w sekwencji. Pomaga to w rozumieniu kontekstu i relacji między słowami. Bez mechanizmu uwagi nic by nie działało.

(źródło obrazu) -
Trenowanie: Pre-training i Fine-tuning:
LLM-y przechodzą przez dwie główne fazy trenowania. W fazie pre-trainingu (wstępnego trenowania) model uczy się ogólnych wzorców językowych z ogromnego korpusu danych tekstowych (takich jak książki, strony internetowe itp.) przy użyciu uczenia nienadzorowanego. Ten etap pomaga modelowi zrozumieć podstawową strukturę języka i powiązania między słowami.Fine-tuning (dostrajanie) następuje po pre-trainingu i jest bardziej wyspecjalizowany. Tutaj model jest trenowany na węższym zestawie danych dostosowanych do konkretnych zadań, takich jak tłumaczenie, analiza sentymentu czy odpowiadanie na pytania. Ta faza często obejmuje uczenie nadzorowane, czasem wzmocnione technikami takimi jak RLHF, aby doprecyzować dokładność modelu w konkretnych zadaniach.
-
RLHF: Uczenie ze wzmocnieniem na podstawie informacji zwrotnych od ludzi
Zbieranie danych:
RLHF zaczyna się od początkowego modelu wytrenowanego za pomocą uczenia nadzorowanego, w którym uczy się on na zbiorze tekstów napisanych przez ludzi pod nadzorem inżynierów. Jednak to wstępne trenowanie może nie idealnie dopasować odpowiedzi modelu do ludzkich preferencji w bardziej subtelnych scenariuszach.
Informacje zwrotne od ludzi:
Aby udoskonalić model, do procesu włącza się ludzkich recenzentów. Recenzenci ci wchodzą w interakcję z modelem, podając prompty lub zadania. Następnie oceniają odpowiedzi modelu lub sugerują lepsze alternatywy. Ta informacja zwrotna jest kluczowa, ponieważ reprezentuje ludzkie oceny tego, co stanowi dobrą lub poprawną odpowiedź.
Trenowanie z informacją zwrotną:
Informacje zebrane od recenzentów są wykorzystywane do dalszego trenowania modelu. Odbywa się to za pomocą metody znanej jako Proximal Policy Optimization (PPO), która jest techniką uczenia ze wzmocnieniem. Model uczy się przewidywać nie tylko na podstawie statystycznych wzorców języka, ale także preferencji i poprawek sugerowanych przez ludzi. Pomaga to modelowi ściślej dostosować się do ludzkich wartości i preferencji.
Iteracyjne doskonalenie:
Proces ten jest iteracyjny, co oznacza, że model może przejść przez kilka rund zbierania opinii i ponownego trenowania. Każdy cykl ma na celu stopniowe udoskonalenie wyników modelu, czyniąc je coraz bardziej zgodnymi z ludzkimi oczekiwaniami i standardami etycznymi.
Wdrożenie:
Gdy model osiągnie satysfakcjonujące wyniki, ocenione przez recenzentów, może zostać wdrożony. Nawet po wdrożeniu konieczne może być ciągłe monitorowanie i sporadyczne ponowne trenowanie z nowymi opiniami ludzi, aby utrzymać wydajność i aktualność modelu.
-
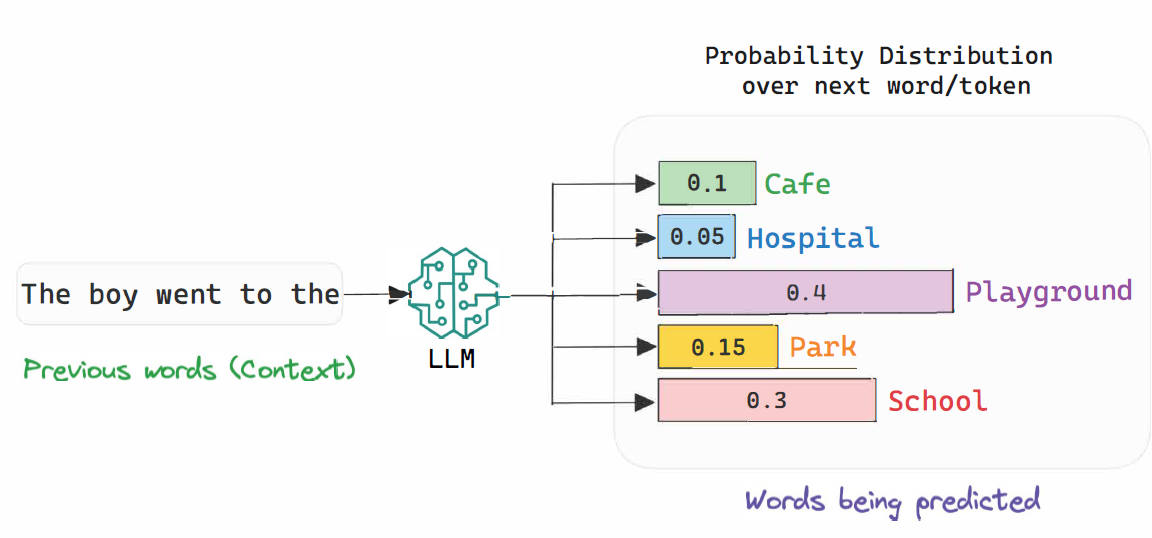
Generowanie tokenów:
Podczas generowania tekstu LLM przewiduje następny token w sekwencji na podstawie otrzymanych danych wejściowych (na przykład całej historii rozmowy lub Twojego pytania). Wiąże się to z obliczaniem prawdopodobieństwa dla każdego możliwego następnego tokena i wybraniem tego o najwyższym prawdopodobieństwie. Proces ten powtarza się dla każdego nowego słowa, aż model zakończy odpowiedź lub osiągnie limit maksymalnej długości.Właśnie dlatego LLM-y zużywają dużo energii — wykonują miliony obliczeń przy każdym przewidywaniu następnego tokena, mimo że w każdym cyklu wybiorą tylko jedno słowo/token.
(źródło obrazu)